Robots.txt – это служебный файл, который служит рекомендацией по ограничению доступа к содержимому веб-документов для поисковых систем. В данной статье мы разберем настройку Robots.txt, описание директив и составление его для популярных CMS.
Находится данный файл Робота в корневом каталоге вашего сайта и открывается/редактируется простым блокнотом, я рекомендую Notepad++. Для тех, кто не любит читать — есть ВИДЕО, смотрите в конце статьи 😉
- В чем его польза
- Директивы и правила написания
- Мета-тег Robots и его директивы
- Правильные роботсы для популярных CMS
- Проверка робота
- Видео-руководство
- Популярные вопросы
Зачем нужен robots.txt
Как я уже говорил выше – с помощью файла robots.txt мы можем ограничить доступ поисковых ботов к документам, т.е. мы напрямую влияем на индексацию сайта. Чаще всего закрывают от индексации:
- Служебные файлы и папки CMS
- Дубликаты
- Документы, которые не несут пользу для пользователя
- Не уникальные страницы
Разберем конкретный пример:
Интернет-магазин по продаже обуви и реализован на одной из популярных CMS, причем не лучшим образом. Я могу сразу сказать, что будут в выдаче страницы поиска, пагинация, корзина, некоторые файлы движка и т.д. Все это будут дубли и служебные файлы, которые бесполезны для пользователя. Следовательно, они должны быть закрыты от индексации, а если еще есть раздел «Новости» в которые копипастятся разные интересные статьи с сайтов конкурентов – то и думать не надо, сразу закрываем.
Поэтому обязательно получаемся файлом robots.txt, чтобы в выдачу не попадал мусор. Не забываем, что файл должен открываться по адресу http://site.ru/robots.txt.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом Яндекса
Disallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articles
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрами
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2
Мета-тег robots и как он прописывается
Данный вариант запрета страниц лучше учитывается поисковой системой Google. Яндекс одинаково хорошо учитывает оба варианта.
Директив у него 2: follow/nofollow и index/noindex. Это разрешение/запрет перехода по ссылкам и разрешение/запрет на индексацию документа. Директивы можно прописывать вместе, смотрим пример ниже.
Для любой отдельной страницы вы можете прописать в теге <head> </head> следующее:

Правильные файлы robots.txt для популярных CMS
Пример Robots.txt для WordPress
Ниже вы можете увидеть мой вариант с данного Seo блога.
User-agent: Yandex Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: romanus.ru User-agent: * Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Sitemap: https://romanus.ru/sitemap.xml
Трэкбэки запрещаю потому что это дублирует кусок статьи в комментах. А если трэкбэков много — вы получите кучу одинаковых комментариев.
Служебные папки и файлы любой CMS я стараюсь я закрываю, т.к. не хочу чтобы они попадали в индекс (хотя поисковики уже и так не берут, но хуже не будет).
Фиды (feed) стоит закрывать, т.к. это частичные либо полные дубли страниц.
Теги закрываем, если мы их не используем или нам лень их оптимизировать.
Примеры для других CMS
Чтобы скачать правильный robots для нужной CMS просто кликните по соответствующей ссылке.
Как проверить корректность работы файла
Анализ robots.txt в Яндекс Вебмастере – тут.
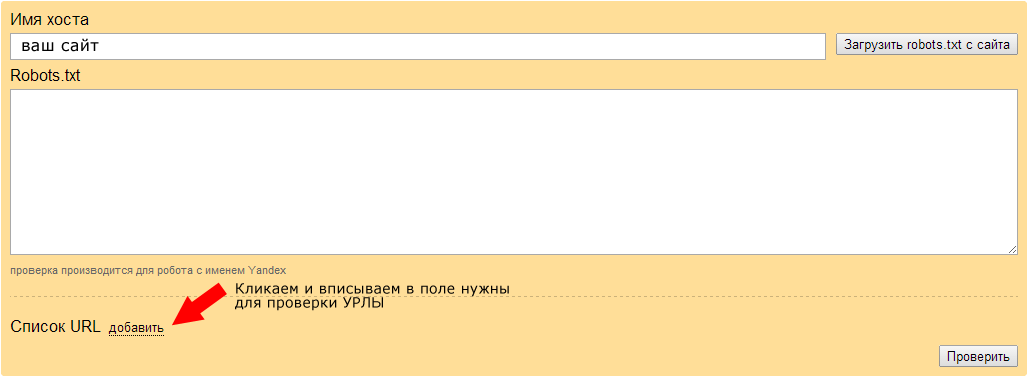
Указываем адрес своего сайта, нажимаем кнопку «Загрузить» (или вписываем его вручную) – бот качает ваш файл. Далее просто указываем нужные нам УРЛы в списке, которые мы хотим проверить и жмем «Проверить».
Смотрим и корректируем, если это нужно.

Популярные вопросы о robots.txt
Как закрыть сайт от индексации?
-
User-agent: Yandex Disallow: / User-agent: * Disallow: /
Как запретить индексацию страницы?
-
User-agent: Yandex Disallow: /page.html User-agent: * Disallow: /page.html
Как запретить индексацию зеркала?
- Никак. Для этого нужно склеить зеркала 301 редиректом.
Для магазина стоит закрывать cart (корзину)?
- Да, я бы закрывал.
У меня сайт без CMS, нужен ли мне robots?
- Да, чтобы указать Host и Sitemap. Если у вас есть дубли — то исходя из ситуации закрывайте их.


