Я изучаю Python и неплохо владею Zennoposter — потому решил более глубоко копнуть тему контента в тех вещах, которые можно посчитать и сравнить в рамках ТОП-50 выдачи по запросу. Вопросов у меня очень много, потому не буду их перечислять, а буду писать итоговые материалы (кстати, если хотите видеть больше коротких и полезных заметок по автоматизации и аналитике в SEO — рекомендую подписаться на мою телегу — ТЫЦ, там есть промежуточные заметки данного исследования).
Я по сути второй раз провожу такие большие (для меня) исследования (первый был о тошноте ключевых слов в Яндексе и Google), потому буду признателен за любую обратную связь и советы по проведению таких мероприятий (ну и за ссылочки — тоже 😉 ).
Цель:
Узнать насколько охват (или ширина) LSI слов и фраз влияет на позиции и каким образом. Возможно найти какие-то закономерности и сделать полезные для себя выводы, а не основываться на «все делают и я делаю». Быть может мы зря тратим время внедряя LSI в текст и мучая авторов своими ТЗ на копирайтинг 🙂
Общие данные о комплексном исследовании контента
Вручную были собраны данные семантического анализа (вхождения ключей, n-грамм, LSI слов и фраз, объем, релевантность и т.д.) по ТОП-50 по нескольким запросам из каждой ниши (в основном СЧ и ВЧ, подробнее о видах и типах ключевых слов) в Яндексе и Google. Потом отдельно сделан срез по ТОП-50, но без учета сайтов, которые в теории могли сильно исказить влияние текстовых факторов (например, огромное ссылочное, другой тип сайта, бешеная социальная активность, огромный ИКС и т.д.), т.е. условно был создан портрет стандартного документа для каждого ключа и отсекались все другие сайты, которые вносили искажения.
Я сейчас пишу статью и страшно представить, сколько часов помощников и моих убито на это всё и будет крайне обидно не получить каких-то выводов 🙂 Статью пишу кусками, и в данный момент я даже не свел данные, потому сам не знаю, что получиться — но любой результат, даже отрицательный — это неплохой опыт.
Какие ниши анализировались
Я разбил ниши по типам документов (соответственно запросы брались такие, чтобы все документы в выдаче соответствовали типу), чтобы можно было хотя бы поверхностно, но посмотреть всего по чуть-чуть.
Интернет-магазины и каталоги
- Аэродизайн
- Элитная недвижимость
Услуги
- Строительство
- Юриспруденция
Информационка (статьи)
- SEO
- Сад и огород
- Строительство
- Юриспруденция
Поиск корреляции
Я использовал корреляцию Пирсона, но ее слабое место — выбросы. Т.е. один выброс может исказить всю картину, но если подкинете формул или алгоритмов мне для изучения — буду признателен.
Условимся по значениям, чтобы никого не напрягать процентами:
- Менее 70% — нет корреляции с позициями;
- 70-80% — слабая корреляция;
- 80-90% — средняя;
- Более 90% — сильная.
Суть исследования важности охвата LSI слов и фраз
А теперь перейдем конкретно к сути именно данного поста.
LSI были получены для каждого запроса через Акварель-генератор. Получается список из монограмм (отдельные слова) и биграмм (фразы из 2 слов). Решил проверить, насколько важно именно количество разнообразных LSI из данных списков и как это влияет на позиции. Я всегда давал довольно большой список LSI (делил на важные и второстепенные) и одной из задач копирайтера была — внедрение как можно большего количества из данных списков (идеально, чтобы важные были все). Это занимает довольно много времени при формировании ТЗ и тяжело для автора.
Пару примеров с разбором по запросам
Для начала покажу несколько графиков с разбором по запросам:
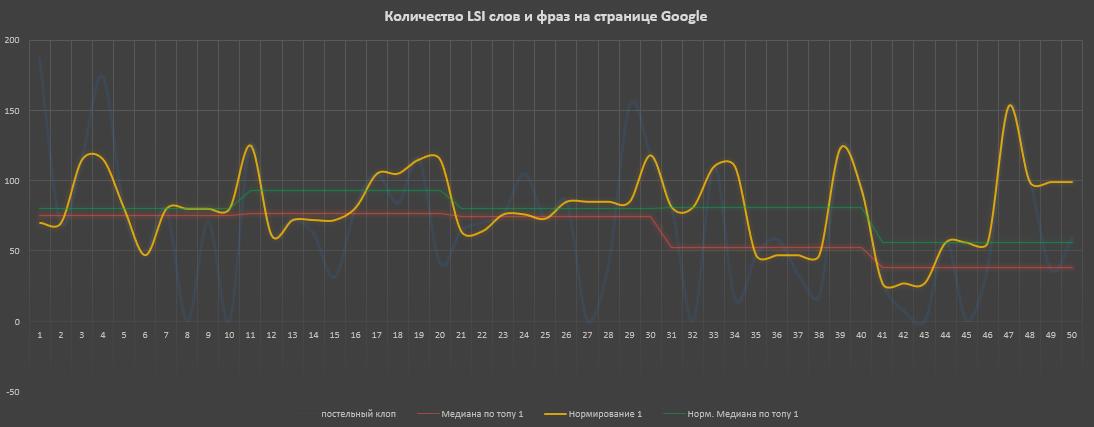
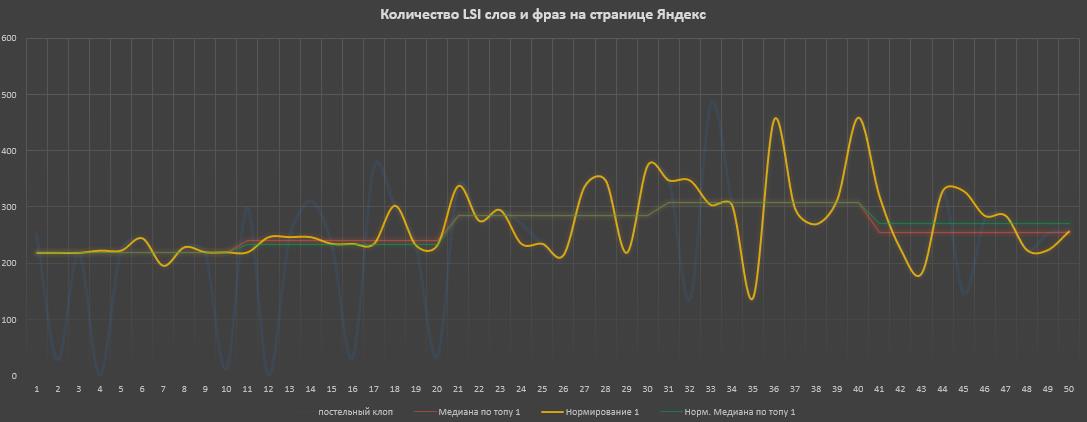
Здесь был взят запрос «Постельный клоп» в нише «Сад и огород», где почти вся выдача — информационные статьи. 2 скриншота, 1 — выдача Google, 2 — выдача Яндекса. Пояснение к графикам по цветам линий:
- Синяя — живая выдача, где был взят наш LSI список и леммататизирован. Контент каждой страницы был спаршен и все слова и фразы так же лемматизированы. Теперь можно посчитать количество совпадение на странице с нашим списком. Провалы до 0 — это сайты, которые не удалось спарсить;
- Оранжевая — из топа выкинуты сайты, которые «вносили искажения» и «не спаршенные»;
- Красная — медиана по значением грязного ТОПа (т.е. по синей линии);
- Зеленая — медиана по «чистому» ТОПу (т.е. по оранжевой линии).
По графикам заметно, что в Google в зависимости от ТОПа медиана растет, как по грязному, так и по чистому ТОПу и имеет среднюю корреляцию (т.е. чем больше охват LSI — тем выше позиции). В Яндексе скорее наоборот — корреляция отсутствует.
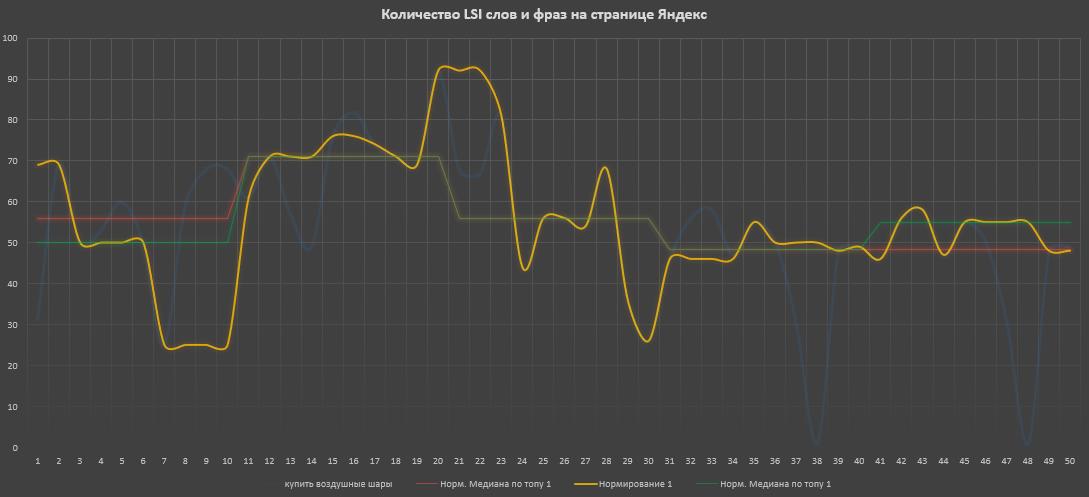
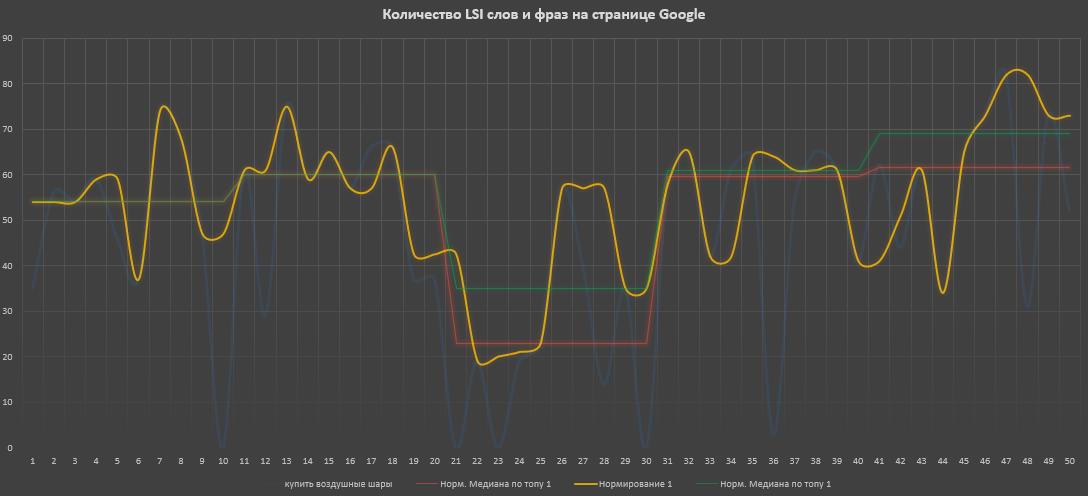
Здесь был взят запрос «купить воздушные шары» в нише «Аэродизайн», запрос явно коммерческий и в выдаче каталоги. 2 скриншота, 1 — выдача Яндекса, 2 — выдача Google. И здесь уже имеем корреляция отсутствует и в Google и в Яндексе, что говорит о том, что по сути значения в ТОП-10 не особо отличаются от значений в ТОП-50. Но мы сейчас говорим об 1 конкретном запросе только. Давайте смотреть по нишам и типам сайтов.
Охват LSI по нишам
Есть же вероятность, что если мы возьмем N запросов из 1 ниши, то может быть там заметим какие-то корреляции. Давайте смотреть. Но чтобы не кидать кучу скринов, я кину те, где в нишах есть что-то интересное, а остальные опишу текстом.
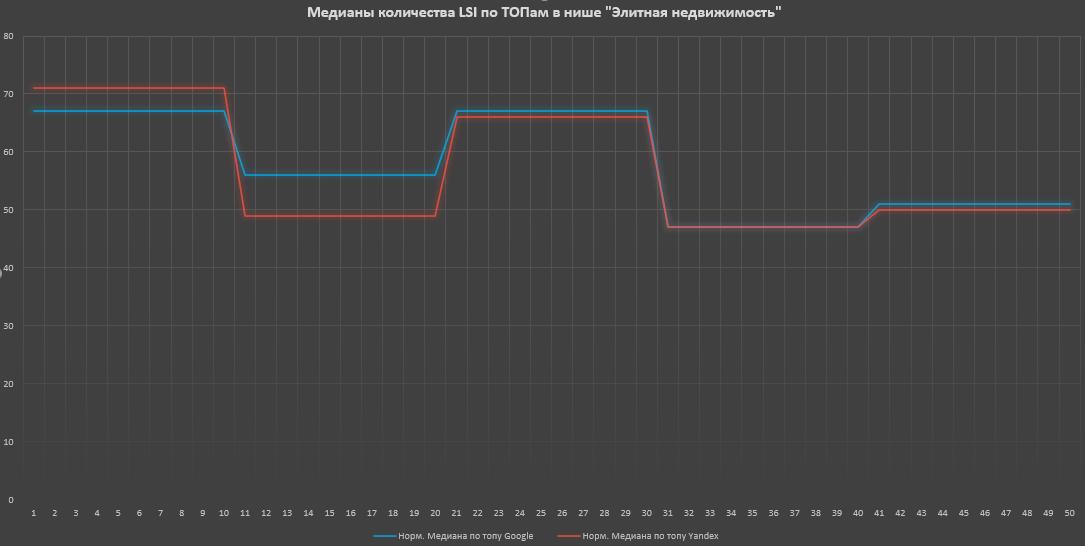
В элитке (ТИП — каталоги) есть корреляция по ТОПам: слабая в Google и отсутствие в Яндексе. Но разница между ТОП-10 и ТОП-50 заметна.
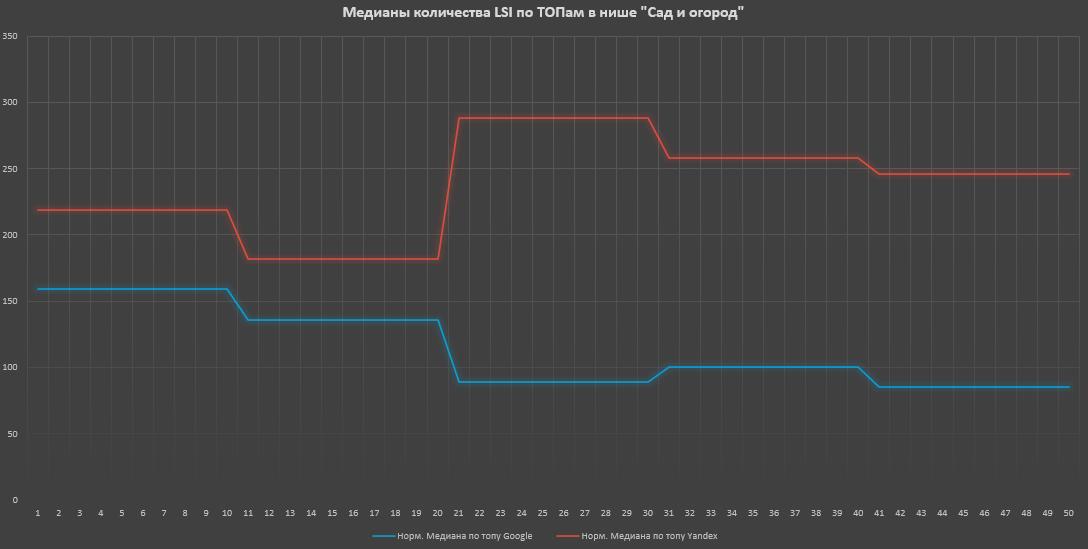
В огородной нише (информационка) корреляция по ТОПам: средняя в Google и отсутствует в Яндексе.
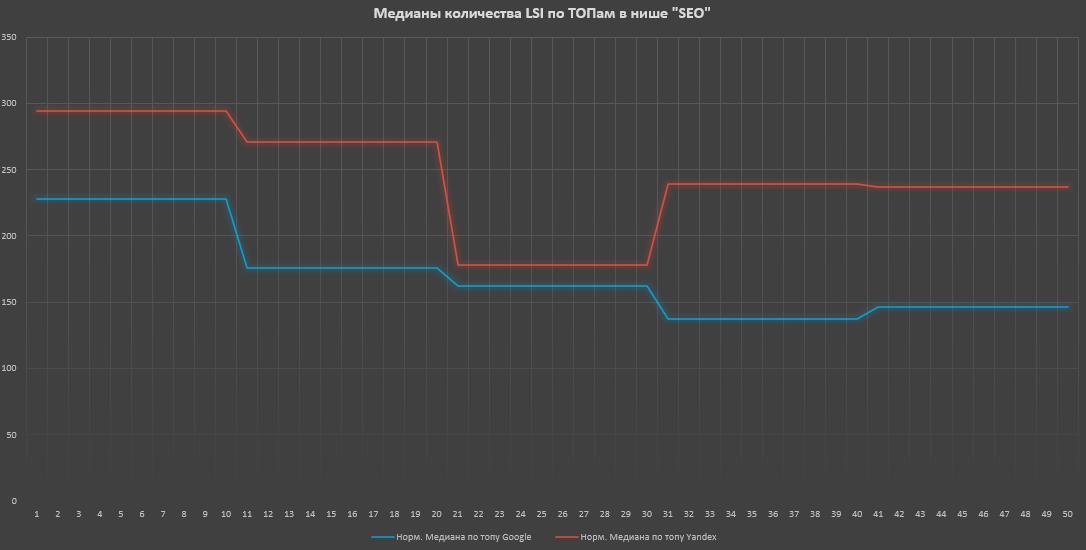
В сеошной нише (информационка) корреляция по ТОПам: средняя в Google и отсутствует в Яндексе (хотя по графику виден провал в ТОП-30, если его исключить — получим так же среднюю корреляцию).
В строительстве в Яндексе слабая корреляция, в Гугле — аналогично. У юристов ситуация в Google средняя корреляция, а в Яндексе слабая. Всё из-за того, что там как и у строителей были и коммерческий и информационные запросы. Но для этого есть 3 сравнение 🙂
Охват LSI по типам документов
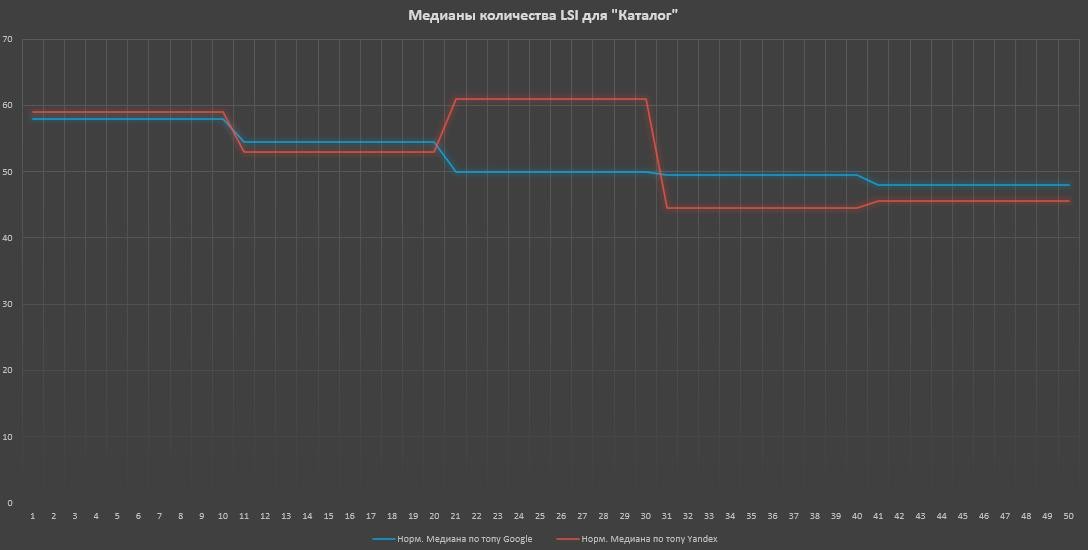
В каталожных страницах имеем сильную корреляцию в Google и слабую в Яндексе. И если вы внимательно смотрели на графики медиан по Яндексу, то заметили странную фигню, которая происходит в ТОП-30 (то провалы, то всплески — если смотреть больше скринов, то ситуация повторяется слишком часто), которые явно портят картину (потому я еще и графики делал). Есть стойкое ощущение, что там находится много пессимизированных сайтов или тех, которые подтягивали другие факторы. Если их откидывать — ситуация будет чуть лучше.
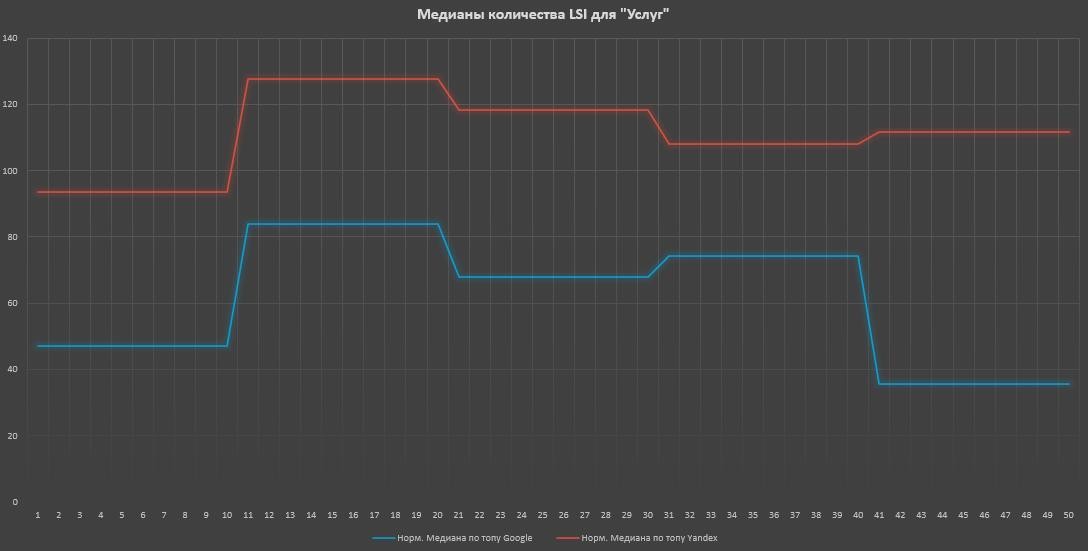
Услуги очень противоречивая штука из-за того, что туда часто примешиваются статьи, где в конце есть возможность оформления заказа, особенно грешит этим юриспруденция. Из-за этого корреляция крайне слабая, потому что вычленить массово такие страницы я не смог. Но если сделать поправку с учетом анализа отдельно каждого запроса — то зачастую в Google мы будем видеть среднюю корреляцию, а в Яндексе ее отсутствие.
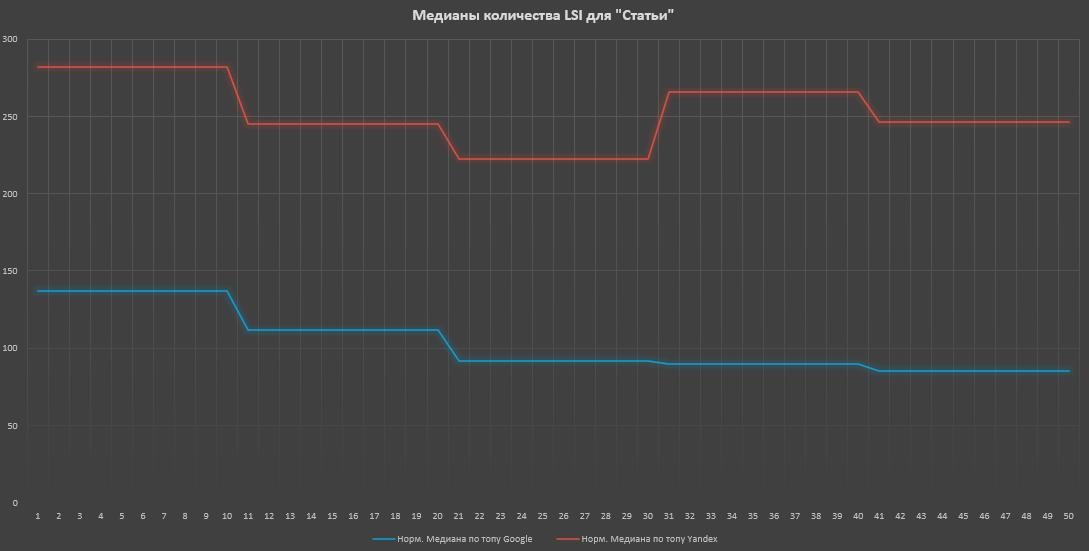
Ну и осталась у нас информационка. Сильная корреляция в Google и отсутствие в Яндексе, но обратите внимание насколько может идти прирост в количестве (да, конечно, это из-за длины текстов).
Выводы
Да, у меня далеко не самая репрезентативная выборка, чтобы делать какие-то заключения, но имеем, что имеем + не видел таких статей у нас в нише. И я немного обобщу и сглажу все проценты, чтобы попробовать описать это словами.

Для большей наглядности я свел вообще все данные в 1 график, чтобы показать просто нормализированные средние значения по всем анализируемым запросам. Обратите внимание, как в ТОП-20 прирастает охват LSI.
| По нишам | Яндекс | |
| Разделил по конкуренции, т.к. заметил закономерность от силы «среднего сайта» по ТОПам. Т.е. если портрет условного среднего сайта — это 500 доменов, ИКС 600, ссылок около 3000, TR около 30 и т.д. — ситуация будет отличаться от ниш, где средний сайт «проще». Будет называть это «конкуренцией». | ||
| Средняя и высокая конкуренция | Чем больше LSI — тем выше позиции во всех случаях. Т.е. сильная корреляция. ТОП-10 лучше, чем ТОП-50 на 40%+. | Аналогичная ситуация в Яндексе. |
| Низкая конкуренция | В 2 поисковых системах не заметил корреляции. | |
Другими словами, чем более конкурентный ТОП — тем больше играет роль охват LSI в 2 поисковых системах. Для низкоконкурентных ниш — можно особо не париться.
| По типу документа | Яндекс | |
| Каталоги | В 2 поисковиках есть корреляция. Есть разница между ТОП-10 (всегда больше охват LSI) и ТОП-50 — но речь идет о разнице в 20%. В Среднем можно ориентироваться на 60 LSI. | |
| Услуги | Самая сложная штука, т.к. часто есть примеси явной информационки и лонгридов в перемешку с короткими услугами. В этой куче никакой корреляции внятной нет или есть, но слабая. В Среднем можно ориентироваться на 80-100 LSI. | |
| Информационные статьи | Сильная корреляция по всей выборке, т.е. больше LSI = лучше позиция. В ТОП-10 на 61% больше LSI, чем в ТОП-50. Ориентиром может быть 120-150 LSI. | Яндекс таким похвастаться не может. Разница между ТОП-10 и ТОП-50 в 14% с уклоном в первую десятку. Но ориентиром будет 270-300 LSI. |
Для каталогов можно не сильно парится по охвату LSI. Корреляция хоть и есть, но речь идет довольно малых цифрах, т.е. вероятность, что вы где-то прям сильно что-то упускаете — минимальная, скорее всего все LSI можно подтянуть просто оптимизацией шаблона страниц.
По услугам — думаю, что более «чистая» выборка дала бы результат максимально схожий с каталогами. Т.е. можно не особо париться.
В информационных статьях всё совсем наоборот — нужно запариться. Для Google хорошо видна корреляция с большой разницей по ТОПам, а в Яндексе вообще нет сайтов с низким показателем охвата LSI в ТОП-50.
Так же хотел бы заметить, что практически во всех случаях в Яндексе (кроме каталогов) в 2-3 раза больший охват LSI, чем в Google. Говорит ли это о том, что Яндекс более требователе к охвату LSI? Думаю да, но это становится сильно заметно только в информационке и, возможно, в услугах.
P.S. Буду очень признателен за комментарии, которые помогут мне лучше разбирать результаты таких исследований, а так же трактовать результаты. Любые подсказки по структуре и подаче таких данных так же приветствуются.


